

مقدمه
بیوانفورماتیک ساختاری که در اصل به عنوان زیستشناسی محاسباتی ساختاری شناخته میشود، از دیگر انواع بیوانفورماتیک شناخته شده مجزا می باشد. می توان استدلال کرد که مقاله اصلی سال ۱۹۵۳ توسط واتسون و Crick در واقع یک مقاله مدلسازی و شاید اولین مقاله بیوانفورماتیک ساختاری است. بنابراین جایزه نوبل سال ۲۰۱۴ برای “مدلسازی چند جانبه” به مارتین karplus، Arie Warshel و مایکل لویت نشان از نقش مهمی در تایید تاثیر بیوانفورماتیک ساختاری بر علوم دارند. در شرح تولد این زمینه ی علمی ، لویت چگونگی مورد نیاز برای تصحیح دقیق مدل tRNA را که توسط کریک برای ساخت مدل واقعی که از خودش بلندتر بود، توصیف میکند. بنابراین، محاسبه، بخش جداییناپذیر از زیستشناسی ساختاری از دوران اولیه خود بوده و نقش فزایندهای در بیولوژی مولکولی و بیولوژی مولکولی با گذر سالها داشتهاست. در حقیقت، از اولین شبیهسازی سیستمهای کوچک و چند پیکوثانیه ای که توسط کمیته نوبل تایید شد، ما اکنون در مرحلهای هستیم که در آن میلی ثانیه یا جستجوهای گسترده توالی و فضای ساختار مورد نیاز است، به عنوان مثال طراحی پروتیین محاسباتی قابلدستیابی است.
طراحی دارو | طراحی محاسباتی + {ویدیو ویژه بیوانفورماتیک دارو}
بیوانفورماتیک ساختاری یا زیستشناسی محاسباتی ساختاری یک رشته در تقاطع بین علوم کامپیوتر، فیزیک، شیمی و زیستشناسی مولکولی است. از لحاظ تاریخی، عبارت “بیوانفورماتیک ساختاری”، پژوهش مبتنی بر اطلاعات، پژوهش مبتنی بر دانش و گروهی از ساختارها را توصیف میکند تا رفتار اماری سیستم تحت بررسی را درک کند. متناوبا، “بیوفیزیک محاسباتی” یک رفتار مبتنی بر نظریه فیزیک مبتنی بر فرضیه سیستمهای مولکولی زیستی را توصیف میکند. فرضیه ergodic تضمین میکند که نتایج از دو نوع رویکرد نسبت به نمونههای اضافی غیر اضافی یا شبیهسازیهای طولانی همگرا میشوند. در حال حاضر، روشهای متعددی از هر دو روش استفاده میکنند. در نتیجه ما به هر دو به عنوان بیوانفورماتیک ساختاری اشاره خواهیم کرد.
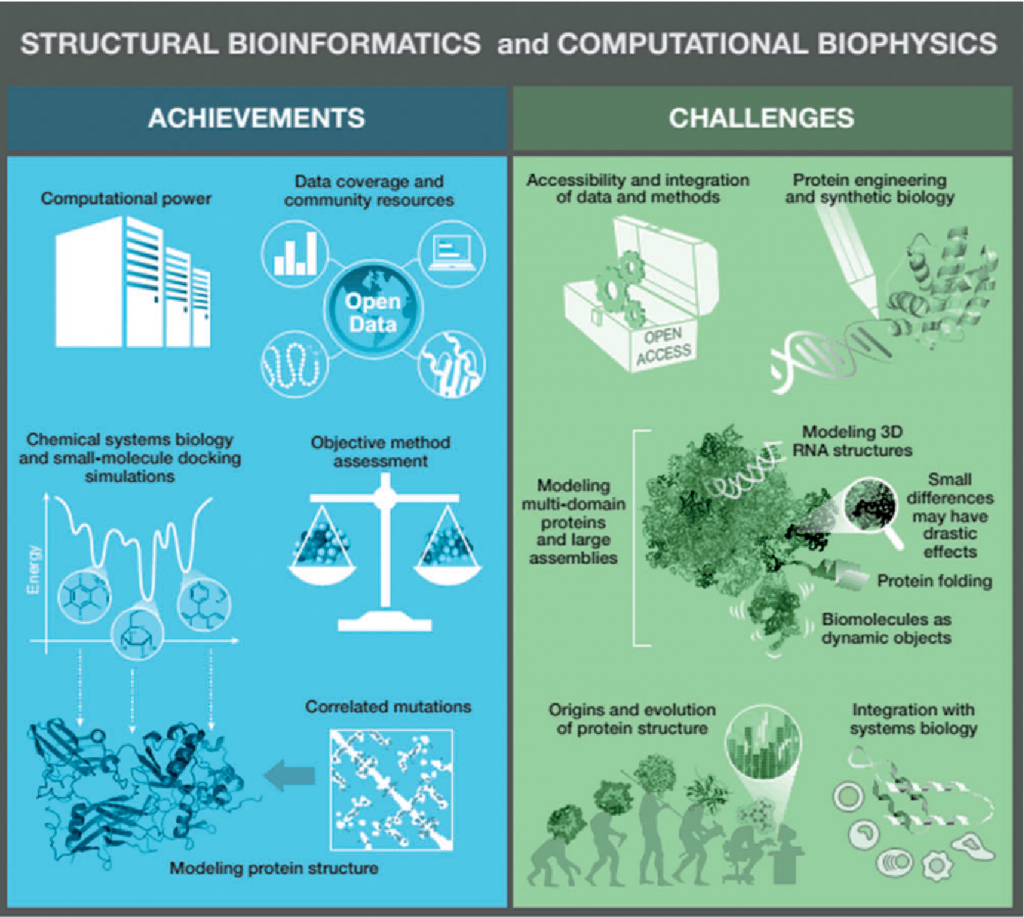
زیست شناسی ، بیوانفورماتیک ساختاری برای درک عوامل موثر بر نفوذ و تعیین نقش مولکول های بیولوژیکی، تاثیر متقابل بین تکامل، سینتیک و ترمودینامیک، عوامل موثر بودن ساختار ماکرومولکول ها و تاثیر آنها بر عملکرد و پایداری و در نهایت توانایی استفاده از همه اینها برای مهندسی، طراحی و بیوتکنولوژی است. در حقیقت، درک کامل از فرآیندهای زیستی باید از طریق درک عوامل موثر بر چنین فرایندهایی در سطح اتمی و گاهی حتی زیر اتمی از بین برود. در این مقاله، ما برخی از برجستهترین دستاوردها در بیوانفورماتیک های ساختاری در طی ۱۰ سال گذشته را مورد بحث قرار داده و چالشهای موجود در این زمینه را مورد بحث قرار میدهیم. بدون شک، موضوعات و مقالات خاص ذکر شده در اینجا با نظر نویسندگان مغرضانه هستند.
تولید لوازم آرایشی{از خط تولید تا بازار فروش}
دستاورد های بیوانفورماتیک
پوشش دیتا های منابع اجتماعی
انقلاب توالی ژنوم انسان در دسترس بودن دادههای توالی در مقیاس بزرگ را نشان میدهد. درک این که توالی به تنهایی برای درک / پیشبینی عملکرد کافی نیست، منجر به ایجاد طرحهای ژنومی ساختاری بزرگ شد که در آن ساختار پروتئینها با شباهت با توالی پایین به پروتیینها با ساختارهای شناختهشده، افزایش پوشش فضای برابر را افزایش داده و مدلسازی فولدینگ دقیق را امکان پذیر میسازد. در دهه گذشته تعداد ساختارهایی که در بانک اطلاعات پروتیین قرار داده شدند ۴ برابر بیشتر از ۱۰۰۰۰۰ ساختار از جمله تعداد بیسابقهای از ساختارهای پروتیینی غشایی شد. PDB- یکی از اولین پایگاههای داده بیولوژیکی و منابع مشتقشده مانند cath، SCOP و PFAM ابزارهای توانمند سازی اساسی برای کل زمین هستند و نگهداری بلندمدت آنها اهمیت زیادی برای این زمینه دارد.
فرمولاسیون آرایشی بهداشتی💄+ نمونه محصولات
توان محاسباتی
افزایش قابلیت دسترسی به قدرت کامپیوتری، برنامههایی را که بیش از چند سال پیش تصور کرده بودند را عملیاتی کرد ، استفاده از واحدهای پردازش گرافیکی یا منبع یابی انبوه توزیعشده با رابط BOINC، دسترسی به روشهای فعلی را افزایش داد. یک پیشرفت هیجانانگیز، مشارکت افراد علاقمند به عنوان حلال مشکلات فعال مانند بازی Foldit است.
روش های ارزیابی هدف
ارزیابی انتقادی پیشبینی ساختار پروتیین، دوره جدیدی را در این حوزه آغاز کرد که یک تست دوگانه برای روشهای پیشبینی ساختار با سایر قسمتهای زیر فراهم میآورد: برهمکنشهای پروتیین، پیشبینی عملکرد، داکینگ پروتیین غشایی یا پیشبینی ساختار خودکار. این امر همچنین منجر به روشهای meta و همکاریهای اجتماعی شد، به عنوان مثال، WeFold
جهش های هم بسته و مدل سازی ساختار پروتئین
دادههای جهش ژنی تغییرات آمینو اسید ها را از دادههای دنباله فعال ساختهاست. سپس چنین نقشههای ارتباطی به عنوان محدودیتهای فضایی برای تولید مدلهایی از پروتیینهای کروی و غشا استفاده میشوند. در مواردی که دادههای دنباله به اندازه کافی امکان استفاده از این روش را فراهم میکنند، سطح بالایی از دقت به دست آمدهاست.
سیستم شیمیایی زیست شناسی
همچنین به عنوان سیستم فارماکولوژی نیز شناخته میشود، ادغام مقادیر عظیمی از دادههای “اومیک ” با روشهای ساختاری در دسترس مانند تشخیص شباهتهای مکان اتصال را می توان برای تغییر و کشف و طراحی دارو مورد استفاده قرار داد.
شبیه سازی داکینگ مولکول های کوچک
شبیهسازی داکینگ به صورت گستردهای مورد استفاده قرار میگیرد. سپس از ساختارهای پیچیده پروتیین برای تولید فرضیاتی در مورد اتصال و گزینش مجازی در مراحل اولیه طراحی دارو استفاده میشود.
ترجمه و گرد آوری توسط تیم بیوانفورماتیک بیوکمپ
منبع
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4271151/
















